(图文|辛西 编辑|辛西 审核|钟磬)近日,华中农业大学信息学院在轻量级音视频分割领域取得新进展。相关研究成果以“LightAVSeg: Lightweight Audio-Visual Segmentation”为题,被国际机器学习会议 International Conference on Machine Learning(ICML 2026)录用。该研究围绕移动端和边缘设备上的高效音视频理解需求,提出了一种轻量级音视频分割框架 LightAVSeg,为复杂场景下发声目标的像素级定位提供了新的解决思路。
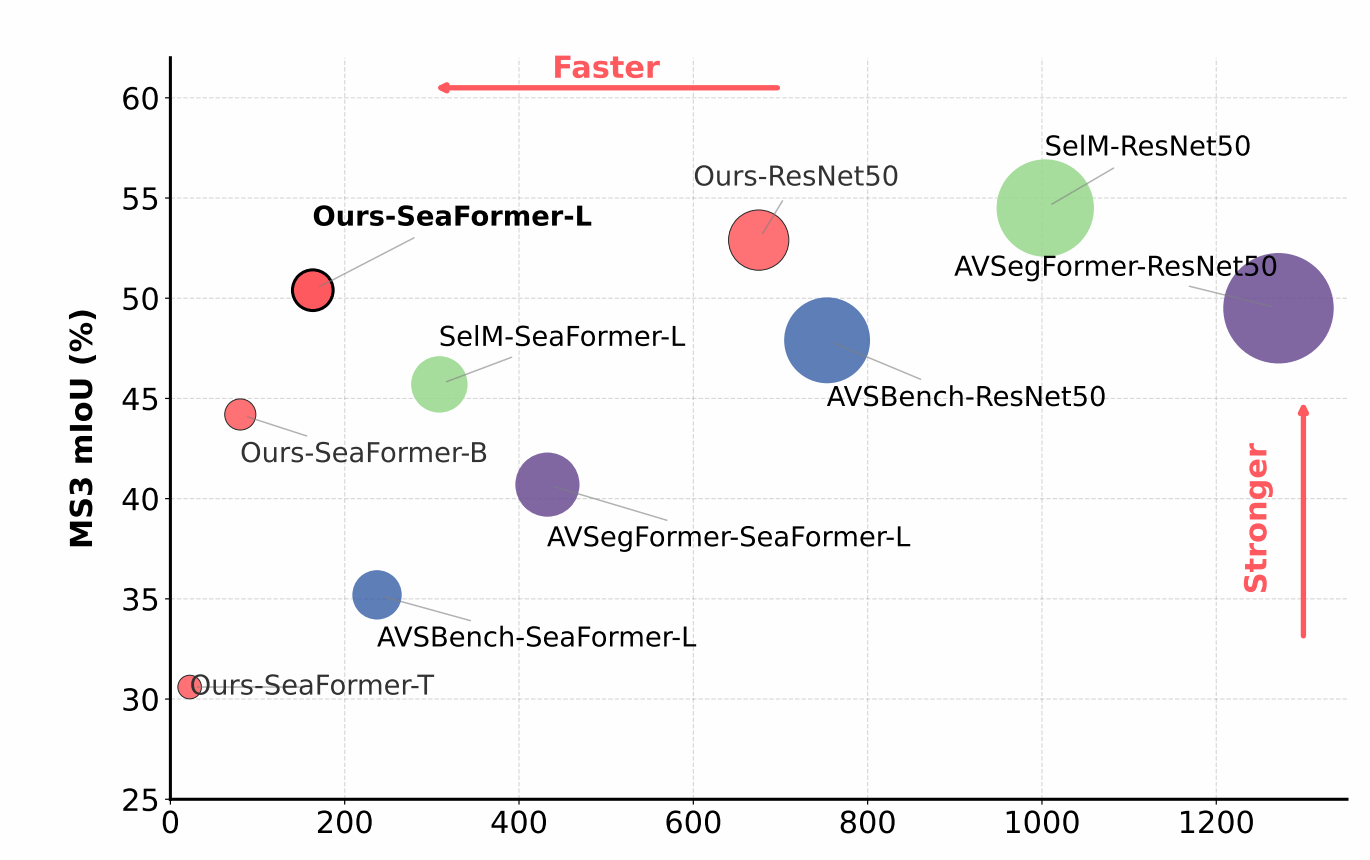
音视频分割旨在根据视频中的声音信息,准确分割出正在发声的物体。例如,在多人说话、乐器演奏、动物鸣叫等场景中,模型不仅需要理解“声音来自哪里”,还需要在图像中精确描绘出对应目标的轮廓。现有方法通常依赖复杂的跨模态注意力机制,通过大量音频与视觉特征之间的密集交互提升分割精度,但这类方法计算开销大、推理速度慢,难以部署到手机、智能终端和增强现实设备等资源受限平台。
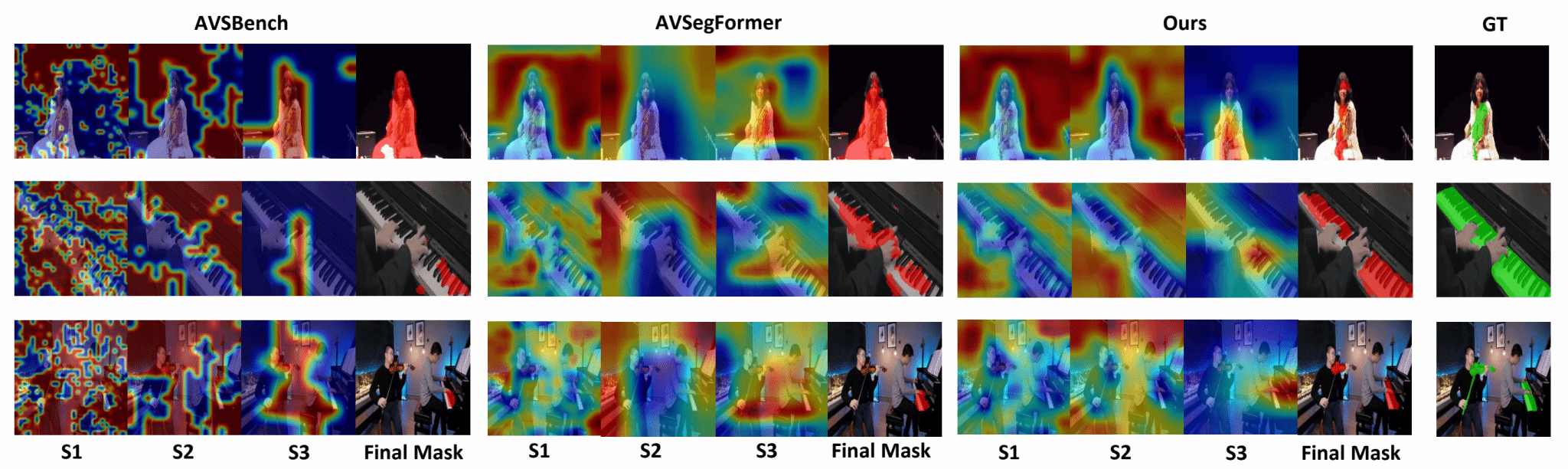
针对这一问题,研究团队提出了 LightAVSeg 框架。该方法没有简单地压缩视觉骨干网络,而是从音频与视觉信息交互机制本身出发,将音视频融合过程拆解为“语义筛选”和“空间定位”两个阶段:一方面,通过互惠式音视频编码器利用视觉上下文逐层更新全局音频语义,使模型更好地判断“哪个物体在发声”;另一方面,通过跨模态融合解码器将音频线索注入视觉层级特征中,从而完成“在哪里分割”的空间定位。相比传统密集注意力机制,该设计避免了高成本的像素级两两匹配,将交互复杂度由平方级降低为线性级,在保证分割效果的同时显著提升了模型效率。
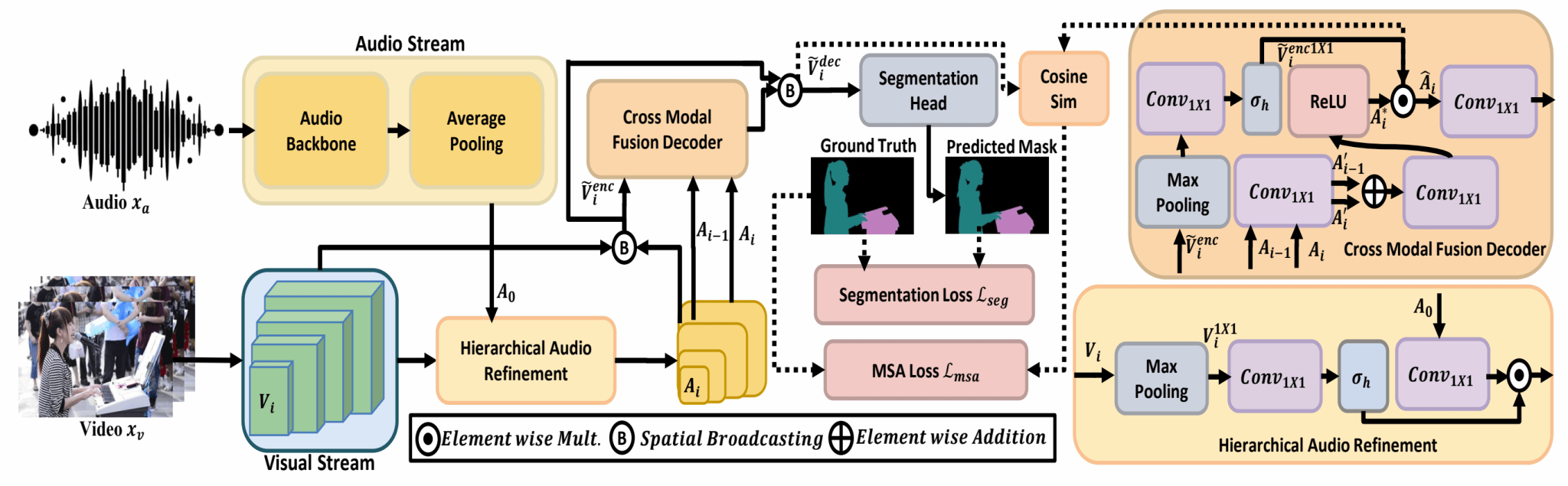
此外,研究团队还设计了多尺度音视频对齐损失,在训练阶段显式约束音频线索与有效视觉区域之间的一致性,引导模型聚焦真正发声的目标区域。该辅助监督仅在训练阶段使用,推理阶段无需额外计算,因此不会增加模型部署成本。
该研究为轻量级多模态感知提供了新的技术路线,可应用于移动端视频编辑、智能交互、增强现实、机器人感知和边缘智能等场景。论文第一作者为华中农业大学信息学院钟磬,华中农业大学信息学院冯在文老师为参与作者。该工作由华中农业大学信息学院、新加坡国立大学、阿德莱德大学等单位合作完成。
论文链接:https://arxiv.org/pdf/2605.08805
【英文摘要】
Audio-Visual Segmentation (AVS) targets pixel level localization of sounding emitting objects in videos. However, existing models rely on dense cross-modal attention with quadratic computational cost, limiting their suitability for resource efficient deployment. Most efficiency oriented methods focus on backbone reduction and overlook the interaction module as the primary bottleneck. This paper proposes LightAVSeg, a lightweight framework that replaces heavy attention with a decoupled design for semantic filtering and spatial grounding, resulting in interaction costs that scale linearly with spatial resolution. Furthermore, we introduce an auxiliary alignment loss to enforce semantic consistency during training with zero inference overhead. Extensive experiments demonstrate that LightAVSeg achieves a new state-of-the-art among lightweight methods: with 20.5M parameters (~1/7 of AVSegFormer), it reaches 50.4 mIoU on the MS3 benchmark and enables efficient inference on a mobile processor.