(图文|辛西 编辑|信息 审核|陈洪)近日,人工智能领域顶级国际会议NeurIPS-2024(Thirty-seventh Conference on Neural Information Processing Systems,CCF-A类)公布论文接收结果,录用了我校信息学院陈洪教授课题组在机器学习理论领域的研究成果。该研究论文题为“How Does Black-Box Impact the Learning Guarantee of Stochastic Compositional Optimization?”,系统分析了黑盒情形对随机组合优化(SCO)算法理论性能的影响。
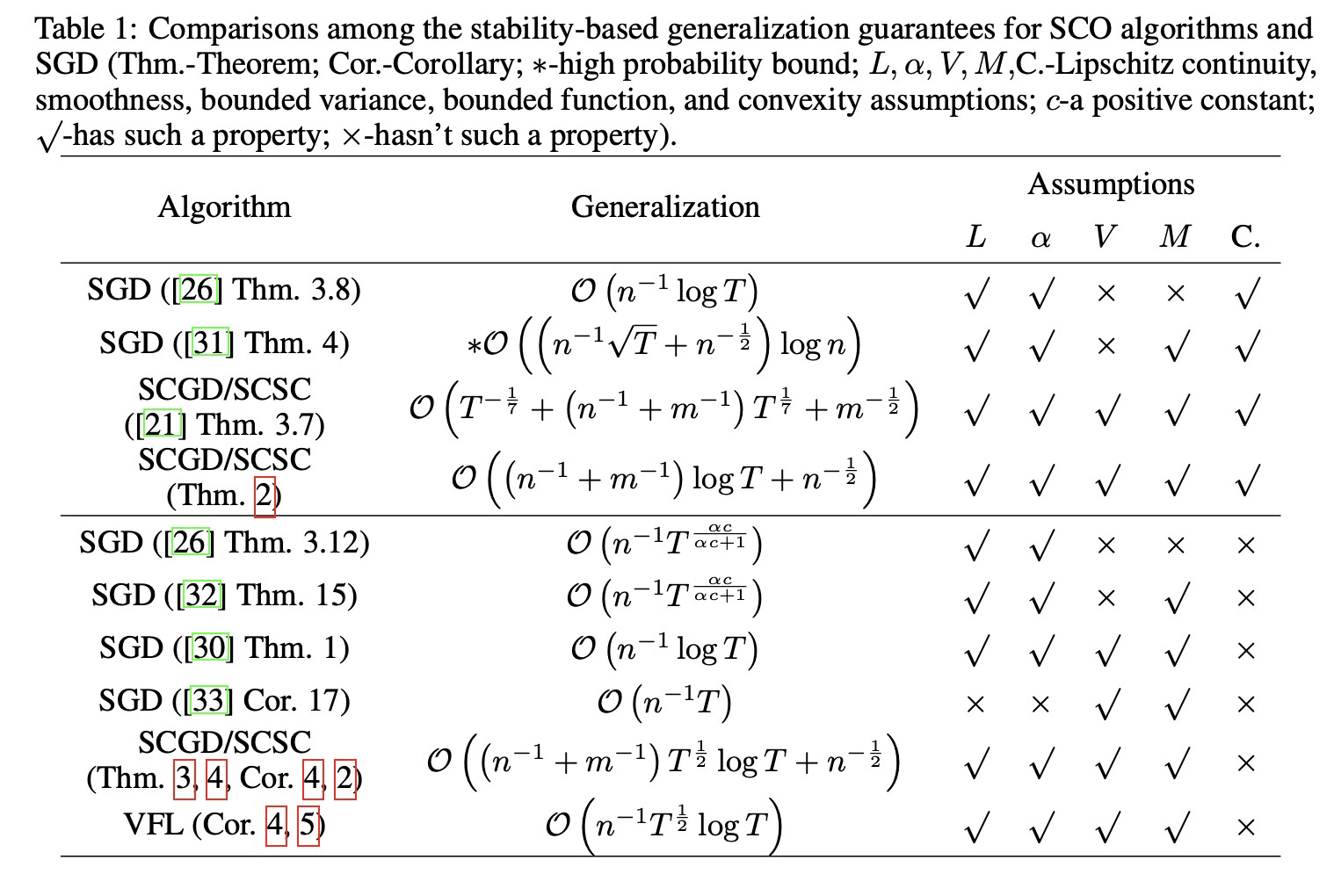
SCO问题涉及人工智能众多领域,如AUC最大化、投资组合优化、强化学习等。从学习理论的角度看,已有文献对梯度已知情形下凸SCO算法进行了理论分析。然而,无梯度(黑盒)情形对SCO算法理论性质的影响机制尚不清晰,值得进一步研究。本文通过对零阶版本的SCGD和SCSC算法进行学习理论分析,揭示了未知梯度的影响。具体来说,研究人员提出一种新的SCO泛化分析框架,在损失函数为凸函数的情况下,该框架基于较温和条件得到了比先前工作更紧的泛化误差上界,并推广得到非凸情况及梯度未知情况下的SCO算法的泛化上界。对比上述结果,从理论上揭示了两个现象:(1)更好的梯度估计会带来更紧的超额风险上界;(2)更大比例的未知梯度会带来对梯度估计质量的更强依赖。最后,研究人员将理论分析应用于两种零阶纵向联邦学习算法,给出其泛化性和收敛性刻画。
信息学院2022级博士研究生陈君为论文第一作者,陈洪教授为通讯作者,吉林大学顾彬教授参与了论文研究工作。该研究得到国家自然科学基金面上项目等资助。
会议链接:https://neurips.cc/
【英文摘要】Stochastic compositional optimization (SCO) problem constitutes a class of optimization problems characterized by the objective function with a compositional form, including the tasks with known derivatives, such as AUC maximization, and the derivative-free tasks exemplified by black-box vertical federated learning (VFL). From the learning theory perspective, the learning guarantees of SCO algorithms with known derivatives have been studied in the literature. However, the potential impacts of the derivative-free setting on the learning guarantees of SCO remains unclear and merits further investigation. This paper aims to reveal the impacts by developing a theoretical analysis for two derivative-free algorithms, black-box SCGD and SCSC. Specifically, we first provide the sharper generalization upper bounds of convex SCGD and SCSC based on a new stability analysis framework more effective than prior work under some milder conditions, which is further developed to the non-convex case using the almost co-coercivity property of smooth function. Then, we derive the learning guarantees of three black-box variants of non-convex SCGD and SCSC with additional optimization analysis. Comparing these results, we theoretically uncover the impacts that a better gradient estimation brings a tighter learning guarantee and a larger proportion of unknown gradients may lead to a stronger dependence on the gradient estimation quality. Finally, our analysis is applied to two SCO algorithms, FOO-based vertical VFL and VFL-CZOFO, to build the first learning guarantees for VFL that align with the findings of SCGD and SCSC.